简介
百度前端技术学院是百度搭建的一个面向在校大学生的前端技术培训平台。鉴于目前大学校园中极少有针对前端开发的专业课程,加之前端开发作为互联网产品必不可少的部分,其重要程度与日俱增的现状,百度前端技术学院的出现非常具有现实意义。
百度前端技术学院主要以发布任务的形式来提高学员的前端水平,可以看到其中的任务都非常贴近真实生产环境的各种需求,完成这些任务能够很有效的提升前端实践能力。但同时,毕竟百度前端技术学院不是作为一个专业培训机构存在,其中的任务在难度设置上还是有比较大的跳跃性。
很遗憾错过了第一期的学员报名,不过由于任务都是公开发布的,我自己也尝试完成了这些任务,并在下面记录了任务中的心得体会。
任务 1 —— HTML、CSS 基础
这一个任务主要为了熟悉 HTML 及 CSS,掌握常见的布局。虽然自己对 HTML 和 CSS 相对比较熟悉,但这部分中还是遇到了两个小问题:
1 图片的 4px 空隙
产生这个问题的代码段重现如下:
<div style="background: #AAA;"> |
这里我们想要实现的效果是 div 完全包裹图片,但实际却会在图片下方产生 4px 的空隙:

产生这 4px 空隙的原因是 img 作为一个行内元素(inline-element),其垂直方向的默认对齐方式是基于基线(baseline)对齐,如果我们在 img 标签两侧插入一些文本,就可以看出图像与文本是底端对齐的(截图中布局为 200% 放大后的效果):

而为了使西文字符中「带尾巴」的字符(如「p」、「q」等)不至于溢出容器,默认情况下基线与行框的下边缘是有距离的,这就造成了 4px 的空隙。有关行框、基线及行内元素的对齐方式,这篇文章做了非常详尽的解释。
解决这一问题的方式也非常简单,修改 img 的垂直对齐方式(vertical-align)为 top 或 bottom 即可。
2 不可忽略的 DOCTYPE
在仔细研究第一个问题的时候,想要在单独的页面中重现这个问题却怎么也重现不出来。无奈到 SegmentFault 提问,才发现这次居然是栽在 DOCTYPE 这个不起眼的标签上。
有时候注意力全部放在文档内容本身,DOCTYPE 标签很容易被忽视。例如一个被我用来写代码段的 demo 文件,居然就一直没有写 DOCTYPE 标签,这个错误直接导致了上面的问题无法成功重现。
虽然是一个很不起眼的问题,但也有必要写在这里给自己提个醒:代码必须写的一丝不苟,才能避免各种「奇葩」的问题。
任务 2 —— JavaScript 基础
1 关于 Email 地址的正则校验
你可能会觉得这是一个很古老的问题 —— 对 E-mail 地址的正则校验每秒钟都会在全世界不同页面的表单中发生成千上万次。但当我用「正则表达式 email」作为关键词在 Google 搜索之后,对得到的结果大失所望。
Google 给出的前两条结果给出的都是同一个表达式:
/^[a-z]([a-z0-9]*[-_]?[a-z0-9]+)*@([a-z0-9]*[-_]?[a-z0-9]+)+[\.][a-z]{2,3}([\.][a-z]{2})?$/i |
然而这个表达式却 根本无法匹配超过 3 个字符的域名后缀,比如 test@zjy.name。另外,就连 二级域名的邮箱地址也无法正常匹配,比如 test@vip.qq.com。后面的几个搜索结果还有的将这条表达式冠以完美经典之名,想想自己的域名邮箱在诸多网站注册受阻,背后必然是一群程序猿 copy 这段正则表达式到自己的代码里,也是醉了。
其实,邮件地址是经过标准规范的,仔细了解过这个标准你会发现,很多看似奇怪的邮件地址都是合法的,比如 my#test=address@test-domain.com.cn
使用过一些奇怪但相对常见的邮箱地址测试后,发现下面这段正则表达式能够比较好的匹配:
^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$ |
其实误判率和严格度本身就是一对矛盾,用户体验和系统稳定的平衡不正是从这种小的方面一点一点建立起来的吗。
2 JavaScript 事件代理
考虑如下情景:一个 ul 中的 li 是动态变化的,这时需要为所有的 li 设置相同的事件。如果使用 addEventListener 方法来逐一处理每个 li,无疑是一件复杂的事。这个时候,我们就可以使用外层容器来代理这个事件:
var ul = document.getElementById("parent-ul"); |
这里就要讲到 JavaScript 中事件的捕获及冒泡。事件捕获及事件冒泡都能完成事件代理的任务,之所以出现两种事件模型,还是浏览器大战导致的。为了兼容的需要,W3C 的事件模型包络了两种方案,即先捕获,再冒泡。
简单来说,JavaScript 中的事件是一个先「由表及里」,而后「由里及表」的过程。「由表及里」指事件的捕获过程,这个过程中事件还没有被触发,而是从根节点向事件目标节点逐层传递,在传递的过程中如果遇到有中间节点处理捕获事件(useCapture 参数为 true)则执行处理函数,然后继续向事件目标节点传递。事件到达目标节点后被触发,而后会「由里及表」逐层向外冒泡。冒泡的过程中会触发中间节点的对应事件类型,冒泡的终点是文档根节点,至此整个事件处理过程结束。文档中如果使用 DOM 的事件属性(如 onclick)来绑定事件,默认被视为绑定在冒泡阶段。另外,还有部分事件是不会进行冒泡传播的。
3 String.split 方法
Javascript 中 String.split 方法总不会产生长度为 0 的数组。如果目标数组中找不到 split 方法参数提供的分隔符,则会产生一个长度为 1 的数组,数组元素为字符串本身,对一个空字符串调用 split 方法,同样则会产生一个长度为 1 的数组,数组元素为空字符串。对以指定分隔符开始或结尾的字符串调用 split 方法,会导致产生的数组长度增加,并且在数组头部或尾部产生空字符串元素。
4 Date 构造方法生成月份 +1 的对象
Javascript 中的 Date 对象共有 4 个构造方法。其中:
new Date(year, month, day, hour, minute, second, millisecond); |
这个构造函数中 month 参数代表月份,特别需要注意这个参数的取值从 0 ~ 11,分别代表 1 ~ 12 月。
5 Autocomplete 中 blur 事件的绑定
在实现文本框的 Autocomplete 特性时,最开始将 blur 事件绑定在文本框上,以实现文本框失去焦点后关闭下拉框。测试发现在点选下拉框项目时,文本框的 blur 事件首先被触发,导致下拉框被关闭,项目选择操作不能成功完成。
为了解决这个问题,首先尝试为文本框及下拉框包裹 div 并在上面绑定 blur 事件,这样下拉框项目点选可以正常完成,但由于 blur 事件是不进行冒泡传播的,因此这种尝试不能完成文本狂失去焦点后关闭下拉框的功能。后来尝试使用捕获事件,发现仍然无法实现下拉框点选和文本框 blur 后下拉框关闭两个功能的完美共存。
在网上搜索了很多相关的文章,最后终于找到了解决方法:在 blur 事件处理中使用 setTimeout 延迟关闭下拉框动作的执行。通过设置延时,将关闭下拉框的动作延迟到 click 事件执行之后,可以完美实现两个功能的并存。
任务 3 —— 综合练习
1 HTML 页面高度
当我们需要让一个 div 的宽度填充整个页面,我们会使用 width: 100% 这样的 CSS 声明来实现。但当我们希望一个 div 的高度填充整个页面,使用 height: 100% 却不能达到目的:div 仍然会包裹其内容,而不会扩展出空白区域。之所以设置 height: 100% 不能实现高度填充,是由于浏览器在计算宽度和高度时采取了完全不同的策略,简而言之,宽度采取的是扩展策略而高度采取的是收缩策略。
在计算页面宽度时,浏览器会尽量让整个页面宽度匹配视口宽度。而在计算高度时,浏览器会尽量收缩页面高度,来包裹所有页面内元素。而当我们以百分比设定元素高度时,实际上是指定的元素相对于父元素高度的百分比,当一个 div 处于顶层,对其设置 height: 100% 是相对于页面高度,而默认情况下浏览器会收缩页面高度来包裹内容 —— 即前面的 div,因此单独设置 div 的 CSS 并不能达到高度填充的效果。为了解决这个问题,我们必须避免页面的高度收缩:
html, |
上面这段 CSS 声明可以避免页面高度收缩,并强制为视口高度。这样我们就可以在页面内部使用百分比来设定元素高度了。
2 对数组属性执行 delete 操作会产生稀疏数组
var a = [0, 1, 2, 3]; |
如果要对数组中的元素进行操作,除非明确要产生稀疏数组,否则不要使用 delete 操作符。上面的示例代码中,使用 delete 操作符进行数组元素删除,删除后数组的长度没有发生变化,并且在删除的元素处产生了 undefined 值。
在对稀疏数组进行操作时,如果不多加留意,就会产生问题,比如:
var a = [0, 1, 2, 3]; |
对稀疏数组直接进行遍历,JavaScript 会跳过数组的间隙。然而,当对这个数组进行持久化再进行读取后会发现,稀疏数组的间隙会被填充为 null,再次对其进行遍历时,则会产生 null 项。
如果要删除数组的元素,同时保持数组是密集的,应当使用数组自身的方法 splice,这个方法会「移除」指定的元素,调整数组长度及被「移除」元素之后各元素的索引,因此不会在数组中产生 undefined 值。
任务 4 —— 最终挑战
1 避免在移动端使用 click 事件
移动设备和桌面设备在前端开发中的区别除了体现在视口尺寸,输入设备的不同也是一个重要方面。桌面设备中常用的输入设备是鼠标这样的相对定位设备,而移动设备中常用的输入设备则是触摸屏这样的绝对定位设备。
绝对定位设备和相对定位设备最大的区别在于绝对设备不存在 无意义的移动。所谓 无意义的移动 是我个人下的定义,打个比方:我们要点击一个链接,在桌面设备上我们需要首先将鼠标指针移动到这个链接上,这段移动是没有产生任何效果的(这里不包括 mouseover 等事件产生的元素特效);而在移动设备上,只要这个链接在视口范围内,我们可以直接点按这个链接,而完全不需要进行 无意义的移动 操作。
这种差异的存在导致 touch 系列事件与 mouse 系列事件的逻辑是存在很大差别的,但另一方面,为了更好的兼容性考虑,移动设备浏览器仍然根据 touch 事件模拟出了 mouse 事件:
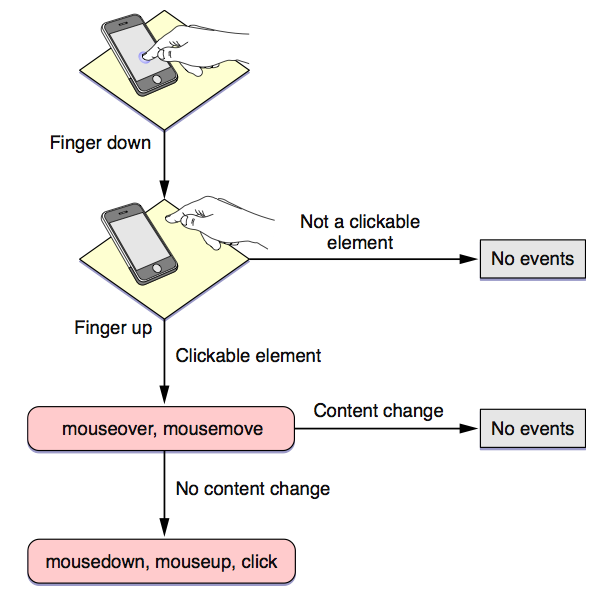
(图片来自网络)
当我们在移动设备屏幕上完成一次点击(Tap)后,浏览器会首先判断目标元素是否是可点击元素(Clickable element)。所谓可点击元素,包括:
- 超级链接
- 表单元素
- 带有区域映射的图像元素
- 绑定了 mousemove, mousedown, mouseup, click 事件的元素,无论是直接使用元素属性的方式绑定还是使用 JavaScript 后期绑定
如果元素为可点击的,那么浏览器便会首先触发该元素上的 mouseover 及 mousemove 事件,如果这两个事件没有引起页面的跳转,那么紧接着会触发该元素上的 mousedown、mouseup 及 click 事件。
说到这里,还是没有讲明白为什么要避免在移动设备上使用 click 事件。其实原因在于用户在点击结束后,mouse 系列事件并不会马上被触发,而是存在 300ms 左右的延迟,这是因为移动设备上还存在两次点击(Double Tap)这个动作(在移动浏览器中的默认动作通常是缩放页面),这 300ms 的延时就是为了判断用户是否是要执行两次点击而设置的。所以说如果你在移动端大量使用 click 事件来进行交互,就会给人一种卡顿的感觉,这就是为什么要避免在移动端使用 click 事件。